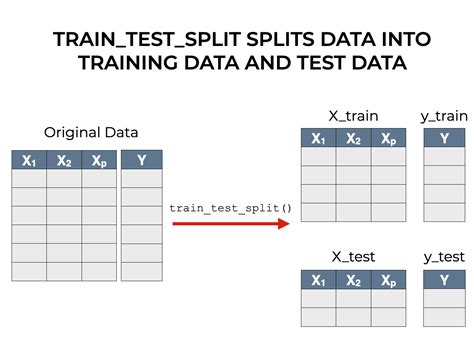
train_test_split drop index|scikit train test : solution from sklearn.model_selection import train_test_split. train_input, test_input, train_target, test_target =. train_test_split(features, target, test_size = 0.25, random_state = 42) # Remove the labels from the dataset. . Plataforma Heroi: Uma ampla seleção de jogos aguarda por você na Heroi, atendendo a todas as preferências dos apaixonados por jogos. Acesso Rápido na Heroi: Entre e jogue sem demora, com um processo de login eficiente e direto. www.heroi.bet: Explore um site intuitivo e bem estruturado, repleto de uma extensa variedade de jogos.
{plog:ftitle_list}
Resultado da Norsemen. 2016 | Maturity Rating: 16+ | 3 Seasons | Comedy. In 790 AD, the Vikings of Norheim have a hectic schedule that includes pillaging, plundering, enslaving others and solving problems with violence. Starring: Kåre Conradi, Silje Torp, Nils Jørgen Kaalstad. Creators: Jon Iver Helgaker, Jonas .
from sklearn.model_selection import train_test_split. train_input, test_input, train_target, test_target =. train_test_split(features, target, test_size = 0.25, random_state = 42) # Remove the labels from the dataset. .
Split arrays or matrices into random train and test subsets. Quick utility that wraps input validation, next(ShuffleSplit().split(X, y)) , and application to input data into a single call for . Learn how to split sklearn datasets with the `train_test_split` function. Featuring examples for similar tools such as numpy and pandas! Using train_test_split() from the data science library scikit-learn, you can split your dataset into subsets that minimize the potential for bias in your evaluation and validation process. In this tutorial, you’ll learn: Why you need to .You could just use sklearn.model_selection.train_test_split twice. First to split to train, test and then split train again into validation and train. Something like this: X_train, X_test, y_train, y_test. = train_test_split(X, y, test_size=0.2, .
In this tutorial, you’ll learn how to split your Python dataset using Scikit-Learn’s train_test_split function. You’ll gain a strong understanding of the importance of splitting your data for machine learning to avoid underfitting or .
train test split index
scikit train test split example
How to Split Data into a Training and Testing Set in Python. To split data into a training and testing set in Python, use the train_test_split function of the Scikit-learn library. Pass the arrays of data to be split as . To use this method you will have to import the train_test_split() function from sklearn and specify the required parameters. The params include test_size : how you want to split the test data by e.g. 0.30% which is 30% of . Train Test Split Using Sklearn. The train_test_split () method is used to split our data into train and test sets. First, we need to divide our data into features (X) and labels (y). . If you want to split the data set once in two parts, you can use numpy.random.shuffle, or numpy.random.permutation if you need to keep track of the indices (remember to fix the random seed to make everything reproducible):. import numpy # x is your dataset x = numpy.random.rand(100, 5) numpy.random.shuffle(x) training, test = x[:80,:], x[80:,:]
When fitting machine learning models to datasets, we often split the dataset into two sets:. 1. Training Set: Used to train the model (70-80% of original dataset) 2. Testing Set: Used to get an unbiased estimate of the model performance (20-30% of original dataset) In Python, there are two common ways to split a pandas DataFrame into a training set and .Adding to @hh32's answer, while respecting any predefined proportions such as (75, 15, 10):. train_ratio = 0.75 validation_ratio = 0.15 test_ratio = 0.10 # train is now 75% of the entire data set x_train, x_test, y_train, y_test = .Thanks @MaxU. I'd like to mention 2 things to keep things simplified. First, use np.random.seed(any_number) before the split line to obtain same result with every run. Second, to make unequal ratio like train:test:val::50:40:10 use [int(.5*len(dfn)), int(.9*len(dfn))].Here first element denotes size for train (0.5%), second element denotes size for val (1-0.9 = 0.1%) and .
from sklearn.model_selection import train_test_split train_input, test_input, train_target, test_target = train_test_split(features, target, test_size = 0.25, random_state = 42) # Remove the labels from the dataset plt.xlim(0,100) plt.plot(test_target , 'g'); . Split dataframe for train_test_split based on indexes. 0. Splitting by indices: I .If None, the value is set to the complement of the train size. If train_size is also None, it will be set to 0.25. train_size float or int, default=None. If float, should be between 0.0 and 1.0 and represent the proportion of the dataset to include in the train split. If int, represents the absolute number of train samples.
scikit train test index split
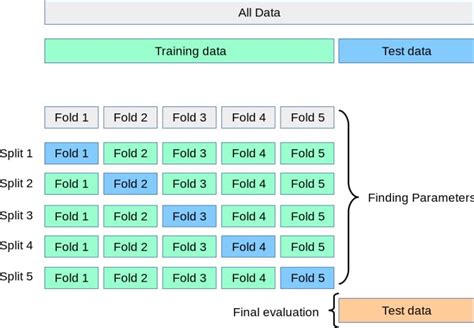
The train-test split procedure is used to estimate the performance of machine learning algorithms when they are used to make predictions on data not used to train the model. It is a fast and easy procedure to perform, the results of which allow you to compare the performance of machine learning algorithms for your predictive modeling problem. Here's an example for continuous/regression data (until this issue on GitHub is resolved).. min = np.amin(y) max = np.amax(y) # 5 bins may be too few for larger datasets. bins = np.linspace(start=min, stop=max, num=5) y_binned = np.digitize(y, bins, right=True) X_train, X_test, y_train, y_test = train_test_split( X, y, stratify=y_binned )
Split. The train_test_split() function creates train and test splits if your dataset doesn’t already have them. This allows you to adjust the relative proportions or an absolute number of samples in each split. In the example below, use the test_size parameter to create a test split that is 10% of the original dataset: The way to rectify this is to do the train test split before the vectorizing and the vectorizer or any preprocessor in this regard should fit on the train data only. Below is the correct way to do this: As can be expected, the number of tf-idf features are less than before because there were some unique words that are only there in the test setIf your data is a pandas dataframe, it is no problem to get the original indices as they are preserved in the splits: from sklearn import datasets from sklearn.model_selection import train_test_split # import some data to demonstrate iris = datasets.load_iris(as_frame=True) X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2) . In order to split my data into train and test data separately, I'm using . sklearn.cross_validation.train_test_split function.. When I supply my data and labels as list of lists to this function, it returns train and test data in two separate lists.
paint testing manual
Below is a dummy pandas.DataFrame for example:. import pandas as pd from sklearn.model_selection import train_test_split from sklearn.linear_model import . The rows for the training set can be selected by dropping the rows in the original dataframe with the same indexes as the test set. def train_test_split(df, frac=0.2): # get random sample test = df.sample(frac=frac, axis=0) # get everything but the test sample train = df.drop(index=test.index) return train, test What Is the Train Test Split Procedure? Train test split is a model validation procedure that allows you to simulate how a model would perform on new/unseen data. Here is how the procedure works: Train test . Step 4: Use the train test split class to split data into train and test sets: Here, the train_test_split() class from sklearn.model_selection is used to split our data into train and test sets where feature variables are given as .
这里,我们只传入了原始数据,其他参数都是默认,下面,来看看每个参数的用法. test_size:float or int, default=None 测试集的大小,如果是小数的话,值在(0,1)之间,表示测试集所占有的比例; from sklearn.model_selection import train_test_split # Split into train and temp (temp will be split into validation and test) X_train, X_temp, y_train, y_temp = train_test_split( df.drop("label", axis=1), df["label"], test_size=0.4, random_state=42 ) # Split temp into validation and test X_val, X_test, y_val, y_test = train_test_split( X_temp . from sklearn.model_selection import train_test_split . There are a couple of arguments we can set while working with this method - and the default is very sensible and performs a 75/25 split. In practice, all of Scikit-Learn's default values are fairly reasonable and set to serve well for most tasks. However, it's worth noting what these defaults are, in the cases .
I'm trying to set up a test_train_split with data I have read from a csv into a pandas dataframe. The book I am reading says I should separate into x_train as the data and y_train as the target, but how can I define which column is the target and which columns are the data? So far i have the following. import pandas as pd from sklearn.model_selection import train_test_split Data . I am splitting a dataset in train and test set using, X_train, X_test, y_train, y_test = train_test_split(X.values, y.values, test_size = 0.20, random_state=99) However the train & test sets have no column names and index names after the split. How to restore this?
May i know how do i drop values in y_train that correspond to x_train after splitting data? For example: I want to drop those values in y_train that are NaN for X_train['Current_ratio'] X_train[' . Split dataframe for train_test_split based on indexes. 3. sklearn train_test_split on pandas. 0. Having problems with splitting a dataframe into . The shuffle parameter is needed to prevent non-random assignment to to train and test set. With shuffle=True you split the data randomly. For example, say that you have balanced binary classification data and it is ordered by labels. If you split it in 80:20 proportions to train and test, your test data would contain only the labels from one .If None, the value is set to the complement of the train size. If train_size is also None, it will be set to 0.25. train_size float or int, default=None. If float, should be between 0.0 and 1.0 and represent the proportion of the dataset to include in the train split. If int, represents the absolute number of train samples. Paso 4: use la clase dividida de prueba de tren para dividir los datos en conjuntos de prueba y entrenamiento: Aquí, la clase train_test_split() de sklearn.model_selection se usa para dividir nuestros datos en conjuntos de entrenamiento y prueba donde las variables de características se proporcionan como entrada en el método. test_size determina la parte de .
# Quick examples to create test and train samples # Using DataFrame.sample() train=df.sample(frac=0.8,random_state=200) test=df.drop(train.index) # Use train_test_split() Method. from sklearn.model_selection import train_test_split train, test = train_test_split(df, test_size=0.2) # Using model_selection() method. from sklearn.model_selection import .Trims the edge_index representation, node features x and edge features edge_attr to a minimal-sized representation for the current GNN layer layer in directed NeighborLoader scenarios. get_ppr. Calculates the personalized PageRank (PPR) vector for all or a subset of nodes using a variant of the Andersen algorithm. train_test_split_edges
scikit train test
Resultado da Kinechan Onlyfans. 4 818 subscribers. View Post. View context. If you have Telegram, you can view post and join .
train_test_split drop index|scikit train test